
Blog posts covering VXLAN with BGP EVPN control plane has been in my plans for a while. This series will possibly be four or five parts. I am hoping to complete all the write-ups within the month of June, bandwidth/time permitting.
There are a number of elements and definitions which we will need to cover briefly before we get into the details. For subsequent sections, I have tried to arrange those in the order, in which i visualize the hierarchy/relations, and which has been of use to me.
Use Case
The widely understood & deployed use case with VXLAN is the extension of L2 segments on top of L3 infrastructure, to enable solutions requiring L2 Adjacency beyond a single rack. This in turn allows VM mobility with flexible workload placement, both within and between DCs. Previously, Stretching VLANs between the Pods within a DC or across DCs, gave rise to a host of issues around the span of failure domain. for e.g. Spanning Tree issues in one part of the network, could affect other parts.
With VXLAN, VLANs would terminate on the Leaf ToR MLAG Pair, configured as VTEPs. The Leaf/Spine underlay itself is L3. The VLANs from one Rack/PoD could be stretched across the DC or between DCs, on top of this L3 underlay, by way of encapsulation – L2 packets are encapsulated and transferred over the L3 underlay. They are de-encapsulated at the destination ToR pair and original frame forwarded to the respective hosts. In this way, Layer 2 adjacency can be achieved beyond a single rack, while curtailing the failure domain to the local rack.
This solves the problem of extending L2 segments across racks/locations. What is left is to find out the location of hosts to which the delivery is to be made. Which VTEP they are sitting behind, and which VTEPs have members in a given VLAN/VNI. In other words, we have a mechanism of delivering L2 frames to a destination host, so we now look into how to locate the hosts which we intend to deliver the frames to. We could learn their location by data plane flooding, or a more elegant mechanism where we use a protocol based control plane, to distribute the information about where the hosts are located/behind which VTEPs they are sitting. This is what BGP EVPN does for us, in a high level summary.
Before EVPN, VXLAN overlay networks used the flood-and-learn model, where the end-host information learning and VTEP discovery were both data-plane based, with no control protocol to distribute end-host reachability info among VTEPs. This solution had scalability challenges, both with regards to flooding, as well as with the requirement to enable multicast in the underlay network. In contrast, MP-BGP EVPN enables control-plane learning for end hosts behind remote VTEPs. It provides control-plane and data-plane separation, and eliminates/reduces flooding in the overlay.
VXLAN
- An encapsulation that allows us to extends Layer 2 overlays, over a Layer 3 network.
- It is a MAC-in-UDP encapsulation, ergo categorized as a MAC-in-IP overlay protocol.
- The original Layer 2 frame is padded with an additional VXLAN header, which adds 50 bytes overhead. This necessitates the use of Jumbo frames in the transport network, to accommodate the frame size which now exceeds 1500 bytes.
EVPN
- Control plane solution that uses MP-BGP. Controller less.
- Data Plane Use: In theory you could use EVPN with almost any data-plane encapsulation, but it is typically used with VXLAN & MPLS.
- Consistent signalled FDB (Forwarding Database) in control plane using MP-BGP (vs. for e.g. flood-and-learn FDB in data plane).
Control Plane for VXLAN – Classification based on Address Learning & Propagation
Overlay info can be exchanged either via underlay (multicast), or via overlay protocol construct like EVPN (Unicast). I have classified these choices below, according to where/how this learning is taking place.
Data Plane dependent
No Control Plane learning – FDB flood & learn, in data plane.
Static (VTEP <> VNI Map) + Multi/Unicast (Address Propagation)
In this model, end-host information learning & dissemination, is data-plane based. There is no control protocol to distribute end-host reachability information, among VTEPs.
- When a traditional switch receives packets on a port, it ends up learning which hosts are connected on the ports (location) as a consequence. Similarly, Initial MAC address learning in this model, happens over data plane. E.g. upon GARP/ARP packet receive.
- There is no propagation of learnt MAC Address via control plane, as in EVPN. Instead, MAC+IP Route is Transmit/Received via (Underlay) Multicast Flood & Learn, (vs. Transmit/Received as Route-Type 2 in EVPN).
- Because address propagation is multicast, so Underlay has to support multicast.
- Each VNID maps to a Multicast Group.
- VTEP flood list is statically configured. e.g. Instead of replication list mapping VTEP/VNI via Route-type 3 packets in EVPN, the mapping is statically configured.
- BUM replication can be done via Head-End/Ingress replication (Unicast), or Underlay multicast.
- When BUM replication is Multicast,
- BUM traffic is encapsulated into multicast VXLAN packets, and transported to remote VTEP switches, through the underlay multicast forwarding.
- Each VXLAN segment, or VNID, is mapped to an IP multicast group in the transport IP network.
- Each VTEP device is independently configured, and joins this multicast group as an IP host, through IGMP. The IGMP joins trigger PIM joins and signalling throughout the transport network, for the particular multicast group.
- The multicast distribution tree for a group is built through the transport network, based on the locations of participating VTEPs.
- When BUM Replication uses HER/Ingress replication
- The VTEP uses a list of IP addresses of other VTEPs in the network to send BUM traffic.
- Frames are unicast to Overlay peer VTEPs.
- Underlay network is multicast free.
- When BUM replication is Multicast,
Data plane Independent
Control Plane learning – FDB signalled in control plane.
There are two ways to achieve this.
-
Controller Based (NSX, Nuage)
Not covered in this (series of) blog posts as the focus is with EVPN.
-
Protocol Based (BGP EVPN)
-
Info Exchange Components:
- Address Family (AFI/SAFI)
- Virtual Network, the address belongs to (Route Distinguisher, Route Target, Route Type)
- Tunnel Encapsulation type.
-
EVPN Responsibilities:
- Address Propagation (Type 2),
- VNI/VTEP Flood List Mapping (Type 3) and
- Mapping Destination to the Egress VTEP.
-
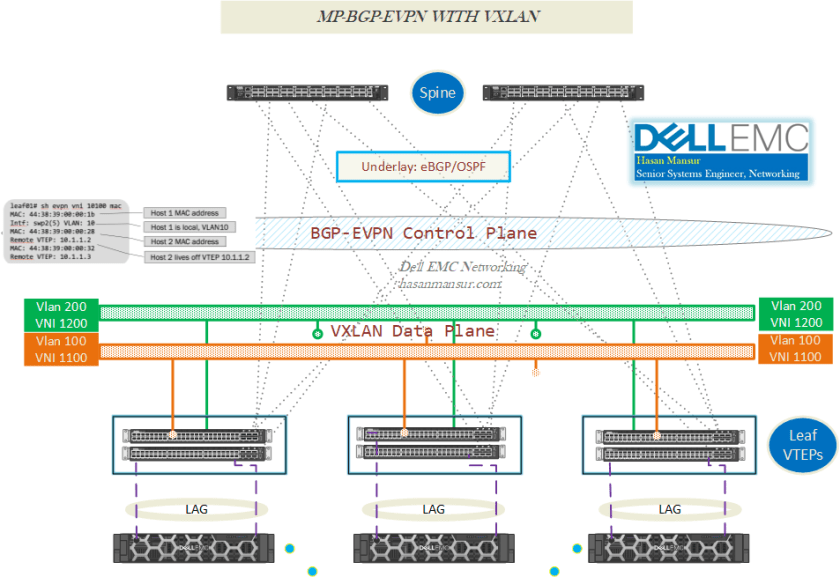
VTEP Functions
A tunnel endpoint is also referred to here, a network virtualization edge (NVE). A VTEP typically has a southbound interface to the LAN segment, and a Northbound interface (VXLAN, not the underlay), which will be used as source VXLAN interface (typically a loopback). The encapsulated packets will have the initiating VTEP as the source IP address and the terminating VTEP as the destination IP address. The ingress NVE adds the tunnel header. The egress NVE strips off the tunnel header.
The Tunnel end-points in VXLAN, have a number of functions/responsibilities to fulfill. These can be summarized as:
-
Host Address Propagation to Remote VTEPs :
- [MAC + Host IP Route] Per VNI : (MP-BGP) Advertise MAC+IP Route to Remote VTEPs, via Type 2 EVPN Routes (Unicast).
-
VTEP Flood List Per VNI :
- Allow each NVE/VTEP, to list the virtual networks it is interested in. Thus,
- VTEPs advertise their VNI membership in BGP
- BGP consolidates and propagates the VTEP list for VNI
- VTEP receives the Remote VTEP list for each VNI
- VTEP can Ingress/Head-end replicate, the traffic to the remote VTEP
- Allow each NVE/VTEP, to list the virtual networks it is interested in. Thus,
-
Map inner payload’s destination address, to appropriate egress NVE’s address.
- e.g. {VNI, MAC} tuple to the NVE’s IP address
Each VTEP performs local learning to obtain MAC and IP address information via (traditional MAC learning/ARP), from its locally attached hosts. The VTEP then distributes this information through the MP-BGP EVPN control plane. Hosts attached to remote VTEPs are learned remotely through the MP-BGP control plane. After the MAC-to-VTEP mapping is complete, the VTEPs forward VXLAN traffic in a unicast stream. Therefore, when a subsequent frame enters the VTEP from a given host, the VTEP
- Checks the VLAN to VNI map to establish the VXLAN into which the frame will be encapsulated.
- Checks the MAC to VTEP map, to determine the IP address of the remote VTEP, to which it has to dispatch the frame.
- Encapsulates and dispatches the frame.
Following table gives a brief overview of the VTEP functions, based on the deployed method.

Underlay + Overlay Peering choices
Function
-
Underlay
- Between ClOS/IP-Fabric members = Non-EVPN addresses
-
Overlay
- Between VTEPs = EVPN Addresses
Options
-
Underlay IGP (e.g. OSPF) & Overlay iBGP
-
Underlay eBGP & Overlay iBGP
-
Underlay & Overlay eBGP.
- Separate (Dual-peering) eBGP sessions, one per address-family.
-
Underlay & Overlay eBGP.
- Single eBGP session (Single peering), separate address-family advertisements. Single Session carries peering info for both overlay & underlay, so can carry EVPN routes too.
- If eBGP sessions are in use between the leaf and spine switches for the underlay routing, the same sessions can be used to exchange EVPN routes.
- The spine switches merely act as “route forwarders” and do not install any forwarding state, as they are not VTEPs.
- Single eBGP session (Single peering), separate address-family advertisements. Single Session carries peering info for both overlay & underlay, so can carry EVPN routes too.
A quick comparison of the underlay options is given below. While this is not exhaustive, it is a useful reference.
-
BGP Vs. OSPF (Underlay)
-
Convergence:
- OSPF may offer faster convergence.
-
Simplicity:
- OSPF is simpler to implement & troubleshoot.
-
Resource consumption:
- BGP is less memory and CPU intensive than OSPF.
-
Scale:
- BGP Scales Better. i.e. Control Plane overhead increase with scale, is more acute for OSPF than for BGP.
-
-
eBGP vs. iBGP
- With BGP, preference is EBGP over IBGP.
- To support ECMP, IBGP requires BGP AddPath.
- To handle peering, IBGP requires route reflectors that mitigate the protocol’s full-mesh requirement.
(Control protocol/BGP) Information exchange
… once peering is established.
Components
Control Protocol must support 3 primary components, for info exchange on Virtual Networks.
-
Network address Family (AFI/SAFI)
- EVPN’s AFI/SAFI is l2vpn/evpn.
-
Virtual network (RD and RT)
- Both RD & RT identify the virtual network, from which a packet comes.
-
Route Distinguisher
- RD + address makes the address globally unique. Derived from IP4 loopback.
- The RD makes overlapping routes from different tenants, look unique to the spine switches. A per-VXLAN 8-byte RD is pre-pended to each advertised route, before the route is sent to a BGP EVPN peer.
-
Route Target:
- Import/Export RT. Which Virtual Network/VNI to import to, which advertisements (from which virtual networks/VNIs) to export.
- RT community distinguishes which routes should be exported from, and imported into, a specific VNI route table on a VTEP.
- If the export RT in the received update, matches the import RT of a VNI instance, on the VTEP receiving the update, the corresponding routes will be imported into that VNI’s EVPN Route table.
- If the RTs do not match, the route will not be imported into that VNI’s EVPN route table.
-
Route Type:
- Because EVPN has already consumed both an AFI and a SAFI, we need another way to further separate the information about unicast and multicast addresses. To accommodate these additional subdivisions, EVPN NLRI is further classified by a Route Type. Route type determines whether the NLRI contained in the BGP update message, concerns a MAC Address, or a whole virtual network. Minimum required to function are Type 2, 3 and 5.
- Type 2: MAC + IP
- MAC + IP Route. Reachability to MAC Address, optionally IP Address. (host reachability)
- The MAC address in the advertisement enables all leaf nodes to know the location of every host, and enables layer 2 reachability, while eliminating data plane learning.
- Adding the IP address onto the advertisement for each MAC address, allows each leaf switch to route as well as perform ARP suppression.
- Type 3: VNI/VTEP Association
- VTEP Discovery
- Reachability within Virtual Network (e.g. used to build replication list, in case of ingress replication of BUM traffic)
- Type 3 also signals BUM Replication Model (via a BGP Attribute, PMSI).
- Type 5: IP Prefix Route, L3 VNI.
- Advertise Prefix, e.g. summarized routes
- Used for External layer 3 connectivity.
- Others : Type 1 & 4
- EVPN uses Route Type 1 (RT-1) and Route Type 4 (RT-4) to handle multi-homed nodes.
- RT-1 tells the network which switches are attached to which common devices or Ethernet segments. An Ethernet segment is defined as either the bridged network to which an NVE is connected, or a bonded link.
- Type 2: MAC + IP
- In summary,
- Type 2 routes are advertising the MAC+IP addresses of end-hosts,
- Type 3 routes are advertising the location of VTEPs in the network.
- Because EVPN has already consumed both an AFI and a SAFI, we need another way to further separate the information about unicast and multicast addresses. To accommodate these additional subdivisions, EVPN NLRI is further classified by a Route Type. Route type determines whether the NLRI contained in the BGP update message, concerns a MAC Address, or a whole virtual network. Minimum required to function are Type 2, 3 and 5.
-
Tunnel encapsulation
-
BGP Encapsulation Extended Community.
- e.g. MAC Mobility extended BGP community. It achieves sub-second convergence during host or VM moves within the data center. This community conveys sequence numbers along with the MAC+IP address and is advertised in the Type 2 routes. The route with the highest sequence number is installed into the EVPN table plus the local bridge forwarding database.
-
In the next part, we shall have a look at how Routing & Bridging functions in the EVPN based VXLAN solution.

This is an excellent write up! Thanks for sharing buddy!
Thanks Chris, much appreciated !