
In the second part, I will focus specifically on VXLAN as a Data Center Interconnect. I intend this iteration to be more general, and then have a third part which is focused on VXLAN options with Dell EMC Networking, including both OS9 as well as the SDN Eco-system solutions – or maybe, i will cover the later in a separate post, depending on the length.
What:
VXLAN is an overlay Virtualisation technology. More precisely, it is an encapsulation method that extends Layer 2 over a Layer 3/IP-based network.
Common overlay protocols today, use either
- MAC-in-MAC encapsulation, such as IETF TRILL, Cisco FabricPath.
- MAC-in-IP can be achieved using NVGRE,VXLAN etc.
Why:
DCI, Layer 2 adjacency across Layer 3 boundaries.
As alluded to in Part 1, DC architectures today are typically Layer 3, which enables scale, interoperability, as well as smaller blast radius/failure domain. Nevertheless, considerations for legacy apps, storage, workload mobility etc. continue to demand Layer 2 adjacency.
VXLAN could be implemented within a DC, or as an interconnect between DCs.
Type/Variety:
VXLAN solutions may be differentiated based on Control-plane/Learning (there are other ways to distinguish them too). The classification along these lines results in:
- Multicast forward/flood based learning
- Protocol based learning
The learning implies Remote VTEP discovery and End stations reachability.
Multicast forward/flood based learning:
The initial IETF VXLAN standard (RFC 7348) defines a
Multicast-based flood-and-learn VXLAN without a control plane.
The original Layer 2 frame is encapsulated with a VXLAN header and then placed in a UDP-IP packet and transported across an IP based network. Thus, it relies on
- Data-driven flood-and-learn behaviour for remote VTEP peer discovery + end-host learning. There is no control protocol to distribute end-host reachability information among the VTEPs. The control plane and the data plane are integrated together.
- Multicast in the network core. The overlay broadcast, unknown unicast, and multicast traffic are encapsulated into multicast VXLAN packets and transported to remote VTEP switches through the underlay multicast forwarding.
Challenges/Issues
- Flooding impacts scalability, as it is a flood-and-learn based L2 technology.
- The requirement to enable multicast in the underlay, may not be attractive/feasible
Underlay
Each VXLAN segment has a VXLAN network identifier (VNID), which is mapped to an IP multicast group in the transport network.
In a traditional L2/VLAN environment, Intra VLAN communication between two hosts would start with an ARP broadcast within the VLAN. Since VXLAN is Layer 2 over Layer 3, this broadcast packet is sent to a multicast group address which is mapped to a VXLAN VNI. Each VTEP that has participating members in that VNI is configured with this multicast group, and participates in PIM routing
The underlay topology could be L3 Leaf & spine. Any unicast routing protocol could be deployed. VXLAN termination is done on Leaf ToRs, and not on the Spine. External Network Access should be via a border leaf block.
BUM Traffic
Underlay IP multicast is used to contain the flooding scope of the participants within the VXLAN segment. This obviously means dependency on multicast in the underlay.
For comparison, the alternate to this mechanism could be unicast with headend/ingress replication, which allows the network to be multicast free. The local VTEP will use IP addresses of other VTEPs to send BUM traffic. These IP addresses are exchanged between VTEPs through static ingress replication configuration.
Overlay
The Layer 2 overlay is created on top of L3/IP underlay, by using VTEP tunnelling mechanism to transport Layer 2 packets. As mentioned,
- It uses flood-and-learn mechanism.
- It does not have a control plane.
Host Detection and Reachability
The VXLAN flood-and-learn spine-and-leaf network relies on initial data-plane traffic flooding to enable VTEPs to
- discover each other
- learn remote host MAC addresses
- MAC-to-VTEP mappings for each VXLAN segment.
After MAC-to-VTEP mapping is complete, the VTEPs forward VXLAN traffic in a unicast stream. The layer 3 routing function is centralized on specific switches (spine switches or border leaf switches).
Protocol based learning:
We will have a look at MP-BGP EVPN as a protocol based learning mechanism for VXLAN.
VXLAN with an MP-BGP EVPN Control Plane, is an alternate to the Flood-and-Learn VXLAN. VTEP peer discovery and endhost reachability information distribution is protocol based. This in turn addresses both the challenges faced by the flood-and-learn VXLAN – i.e.
- Scalability
- Containing flooding
Advantages
There are additional benefits – the following features are vendor dependent and may vary between different VXLAN solutions. I am including these below as some of these will become relevant when I discuss the VXLAN solutions from Dell EMC & its SDN partners like Pluribus & Cumulus.
- Multi-vendor Interopetrability: As it provides a control plane based on industry standards, MP-BGP EVPN allows multivendor interoperability.
- Active-Active multi-homing at Layer 2: VLT/MLAG/VLAG pairs for dual homing of network endpoints, at the leaf. Both VLT/MC-LAG peer switches would act as a single logical VTEP, and participate in the BGP-EVPN operations as Active Forwarders.
- Distributed Anycast Gateway: Each leaf is assigned the same Gateway IP + MAC addresses for connected subnets/VLANs i.e. they share VIPs/vMACs. The leaf switch/pair therefore is the L3 boundary as a distributed (instead of centralized) gateway, and routes all traffic – with both peers being Active Forwarders.
- VXLAN routing: The ability of the leaf switches to do VXLAN routing is dependent on the chip. Single pass (Native) VXLAN routing using RIOT profiles, would become more accessible with the next gen chipsets.
- Dynamic Tunnel Discovery: Remote VTEPs are auto discovered, and VXLAN tunnels are auto provisioned.
- Data-plane IP and MAC learning: EVPN address family carries both L2 & L3 reachability information, which means it facilitates integrated bridging and routing in VXLAN overlays.
- BUM Traffic Handling: In situations requiring the flooding of frames, e.g. MAC aging, L2 broadcast etc., the VTEP replciates the frame in hardware and unicasts the frame to all other VTEPs which have members in the same segment.
- ARP/ND suppression: Leaf ToRs upon discovering remote IP and MAC addresses, populate their respective ARP tables. They respond directly to any local ARP queries, which eliminates the flooding of ARP requests. Thus, Control-plane distribution of MAC/IP addresses enables ARP suppression in the fabric for Layer 2 extensions between racks.
- Conversational ARP/ND learning: Only the active flows are programmed into the forwarding plane. This optimises utilization of hardware resources, as the number of cached ARP entries is significantly reduced. Thus, the control plane could end up holding more host entries than what the hardware table can support. When there is sufficient space in hardware, all host entries are programmed. When there is no space, conversational learning executes and starts aging out the inactive entries.
- VM mobility support: Upon a VM move, the leaf switch discovers & learns its addressing information via data plane learning. This reachability info is then advertised to its peers, which update their forwarding tables accordingly. this enabled optimized convergence in the network.
- Multi-tenancy: Traffic isolation across DCs between L2/L3 domains.
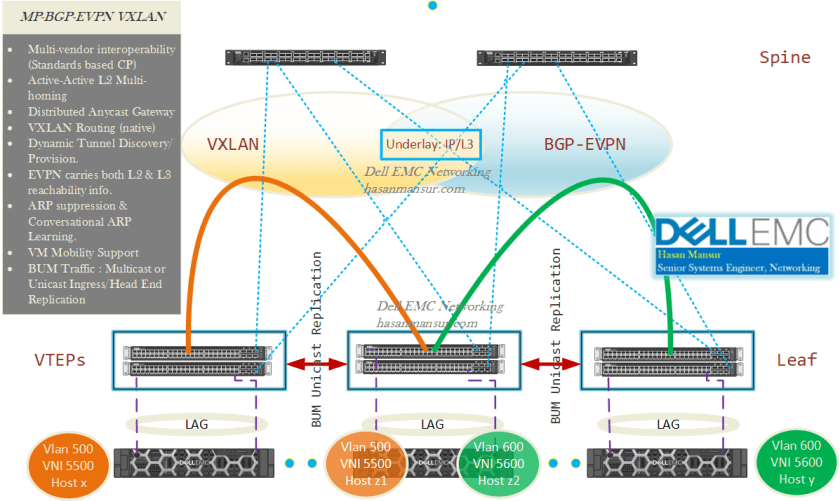
Underlay
Underlay is traditional L3, and could be built using any unicast routing protocol. VXLAN termination is done on Leaf ToRs, and not on the Spine. External Network Access should be via a border leaf block.
BUM Traffic
In a layer-2 Network, MAC address learning is achieved by flooding frames with unknown unicast addresses on all ports which are members of that VLAN. For VXLAN, one or more IP multicast groups are set up to carry BUM traffic to VTEPs associated with a given VNI. Each VTEP needs to be a member only of those VNIs in which it has participating hosts. It does not maintain MAC address tables for VNIs in which it has no local members.
This approach means that the underlay must support IP multicast. Where this is not desired or possible, the alternate is Ingress/Head End Replication, which takes incoming BUM traffic and sends a single unicast copy to each of the VTEPs receiving traffic for a given VNI.
Ergo, the options are
- PIM/Multicast
- Head-end/Ingress Replication: (Multicast Free Underlay) BUM traffic sent as unicast. VTEP IP addresses are exchanged between VTEPs through BGP EVPN or static maps.
Overlay – Data Plane
VXLAN
Overlay – Control Plane
BGP EVPN is an extension to MP-BGP. It is controllerless, and utilises an MP-BGP address family (L2VPN) and NLRI for advertising L2 MAC addresses for endpoints, and mapping them to IP addresses.
Host Detection and Reachability
With MP-BGP EVPN,
- Each VTEP performs local learning to obtain MAC address (though traditional MAC address learning) and IP address information (based on ARP snooping) from its locally attached hosts.
- The VTEP then distributes this information through the MP-BGP EVPN control plane. Hosts attached to remote VTEPs are learnt through the control plane.
This approach addresses both flood based end-host learning, as well as end-host reachability information distribution.
————-
In the next part, I will look at VXLAN deployment with Dell EMC Networking. I might however, post on Pluribus Cloud Fabric before we get to part 3.

Thank you for this series on DCI. I am very curious about part 3. Can we expect it soon?
Hi Mark, thanks for the comment. I was holding back as it occurred to me I could try and incorporate IPInfusion, another of our SDN partners into the post. part 3 focus was initially on Dell EMC, Pluribus, Cumulus & Big Switch. However, after your comment, I shall go ahead with the post as is, and do a followup part 4+ for other solutions. Expect it on Tuesday next week.